Les fondements scientifiques de Pollitics
Pollitics s'appuie sur un programme de recherche autour de la génération exacte de populations synthétiques, de la modélisation en espace latent de structures observées et de la comparaison de signaux simulés à des résultats externes.
Des statistiques agrégées à des populations synthétiques cohérentes
Le point de départ n'est pas un ensemble de personas fictionnels. C'est un problème de génération sous contraintes : comment générer des populations qui respectent les structures démographiques observées tout en évitant des combinaisons peu plausibles (par exemple d'âge, de profession, de revenu, de logement et de variables politiques). Cette exigence vaut pour les structures socio-démographiques, mais aussi pour toutes les autres caractéristiques prises en compte pour définir une population, comme des profils psychologiques ou des comportements d'achat.
Des populations structurées au sondage virtuel
Une fois qu'une population reste cohérente au niveau structurel, il devient possible de l'interroger via des workflows de modèles de langage contrôlés. Pollitics utilise cette couche pour faire émerger réactions, objections, hésitations et effets de cadrage, pas pour affirmer qu'une réponse simulée équivaut à un fait humain observé.
Pourquoi il faut parler à la fois de validation et de limites
Un panel synthétique n'a de valeur que si ses sorties restent interprétables face à des références externes. C'est pourquoi le développement de Pollitics est centré sur des benchmarks de validation, sur la préservation des corrélations et sur l'explicitation des limites : l'objectif est un instrument exploratoire sérieux, pas une promesse opaque de certitude.
Fondements scientifiques
Pollitics s’appuie sur une ligne de recherche qui combine génération exacte de populations synthétiques, modélisation en espace latent de structures observées et validation face à des signaux issus de sondages humains. L’objectif n’est pas de prétendre prédire parfaitement la société, mais de proposer une couche de simulation scientifiquement fondée, explicite sur son périmètre et sur ses limites.
Des populations synthétiques exactes
La première couche de la pile Pollitics est un générateur de population sous contraintes. Au lieu d’échantillonner des répondants fictionnels isolés, le système construit des populations synthétiques sous contraintes démographiques et structurelles explicites. En pratique, cela signifie que l’âge, la profession, la structure familiale, le statut résidentiel, les variables politiques, le revenu ou toute autre caractéristique sont générés conjointement sous exigences de cohérence, au lieu d’être assemblés indépendamment.
Une partie centrale de ce travail consiste à introduire une représentation latente apprise à partir de structures agrégées réelles. L’espace latent ne remplace pas les contraintes ; il les complète en aidant le générateur à éviter des combinaisons peu plausibles et à préserver la géométrie du monde socio-démographique d’origine.
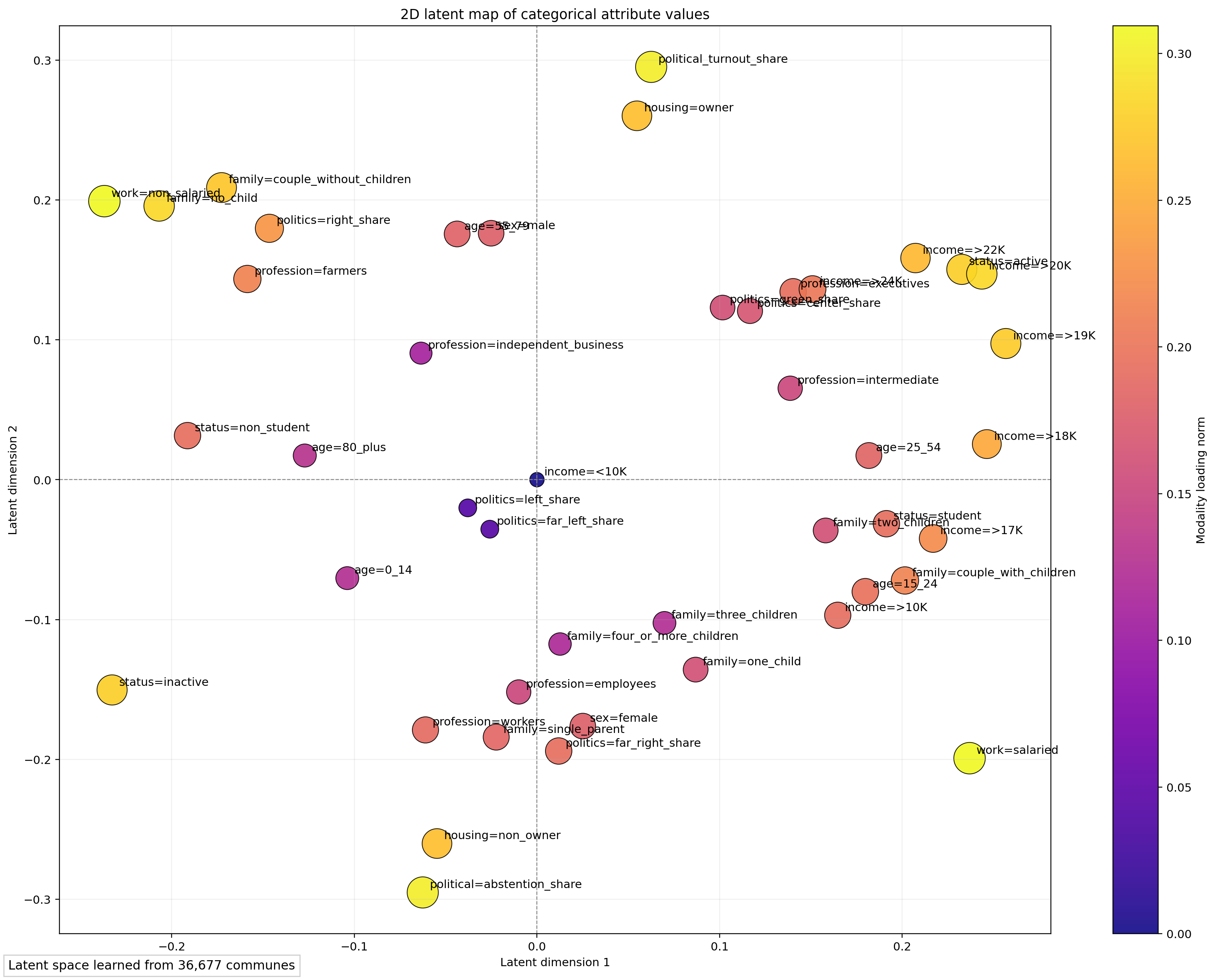
Ce qui importe ici n’est pas la coordonnée exacte d’un libellé, mais l’organisation visible de l’espace. Les modalités de revenu élevé se regroupent près des professions d’encadrement et d’une plus forte stabilité résidentielle ; les structures d’âge et de famille forment leurs propres voisinages ; les variables politiques occupent des positions reflétant les contextes sociaux dans lesquels elles apparaissent habituellement. C’est ce type de régularité latente qui aide Pollitics à générer des populations cohérentes au niveau micro.
Validation externe
Une population synthétique n’est utile que si son comportement aval reste intelligible lorsqu’on le confronte à des références externes. Pour cette raison, Pollitics évalue aussi ses sorties de sondage virtuel en se comparant à des résultats de sondages humains publiés. Cette comparaison n’est pas présentée comme une preuve que les résultats synthétiques égalent une vérité humaine en toutes circonstances ; elle sert de benchmark pour vérifier que le modèle reste directionnellement aligné sur des questions publiques réelles.
L’exemple ci-dessous provient de la question « Les personnes devraient-elles pouvoir se réfugier dans d’autres pays pour échapper à la guerre ou à la persécution ? ». Les barres comparent des proportions IPSOS publiées à des résultats de sondage virtuel obtenus à partir de populations synthétiques issues du moteur de génération de Pollitics.
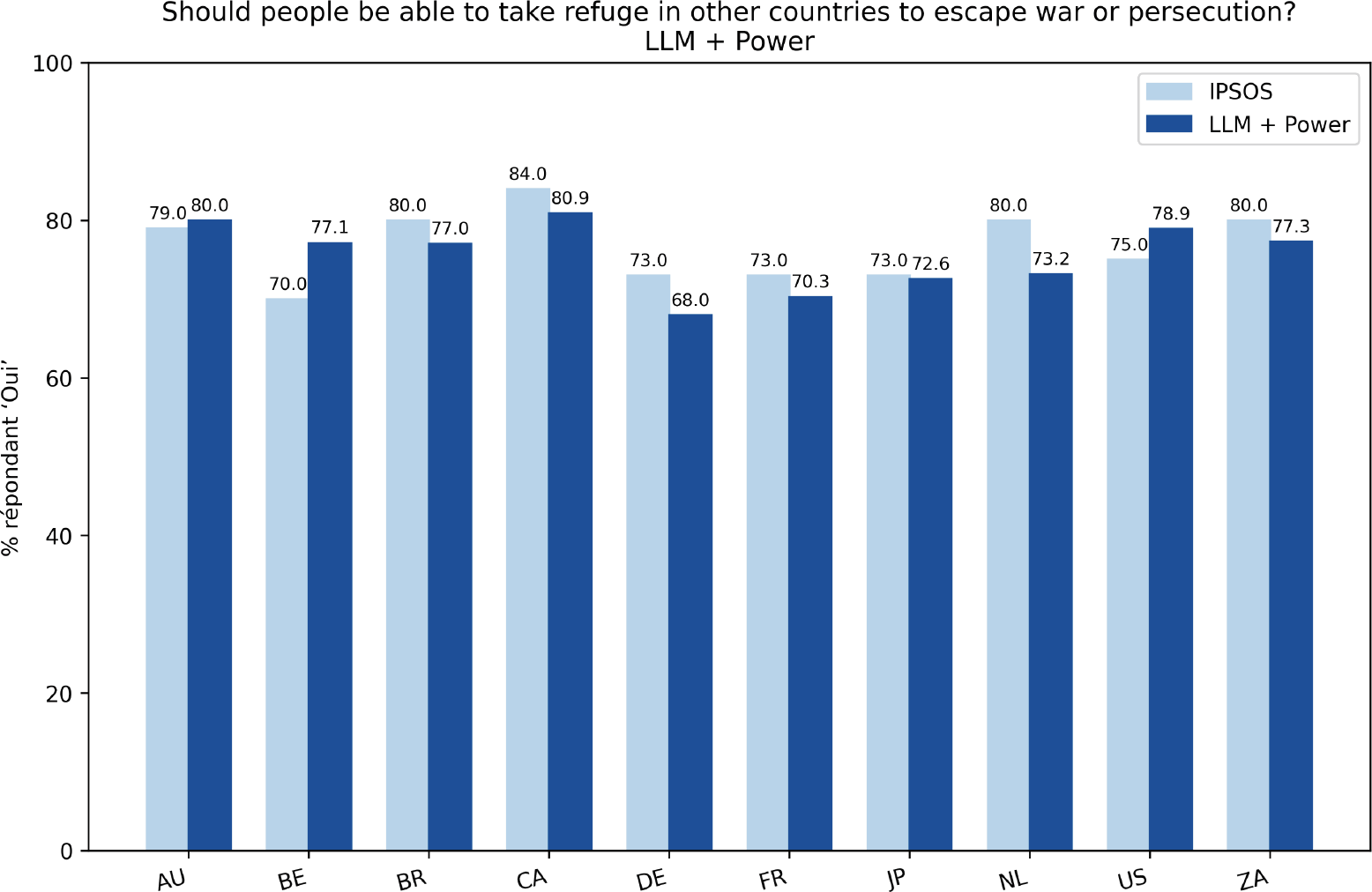
Le signal important ici est la stabilité du motif entre pays. Le pipeline synthétique ne s’écrase pas sur une réponse générique unique ; il préserve une variation inter-pays tout en restant proche du benchmark humain sur une question publique très interprétable. Méthodologiquement, c’est un indice que la couche population et la couche de questionnement comportemental interagissent de façon extérieurement lisible.
Préserver les corrélations lors de la synthèse
Une faiblesse fréquente des systèmes de données synthétiques est de bien reproduire les marges tout en détruisant discrètement la structure de dépendance entre variables. Pollitics cherche explicitement à éviter cet écueil. L’espace latent n’est pas utilisé seulement pour placer des modalités dans une géométrie abstraite, mais aussi pour préserver les schémas de co-mouvement qui rendent une population réaliste.
La heatmap ci-dessous est un exemple de ce type de résultat sur un autre dataset : même après synthèse, des corrélations positives et négatives fortes restent visibles au lieu d’être aplaties.
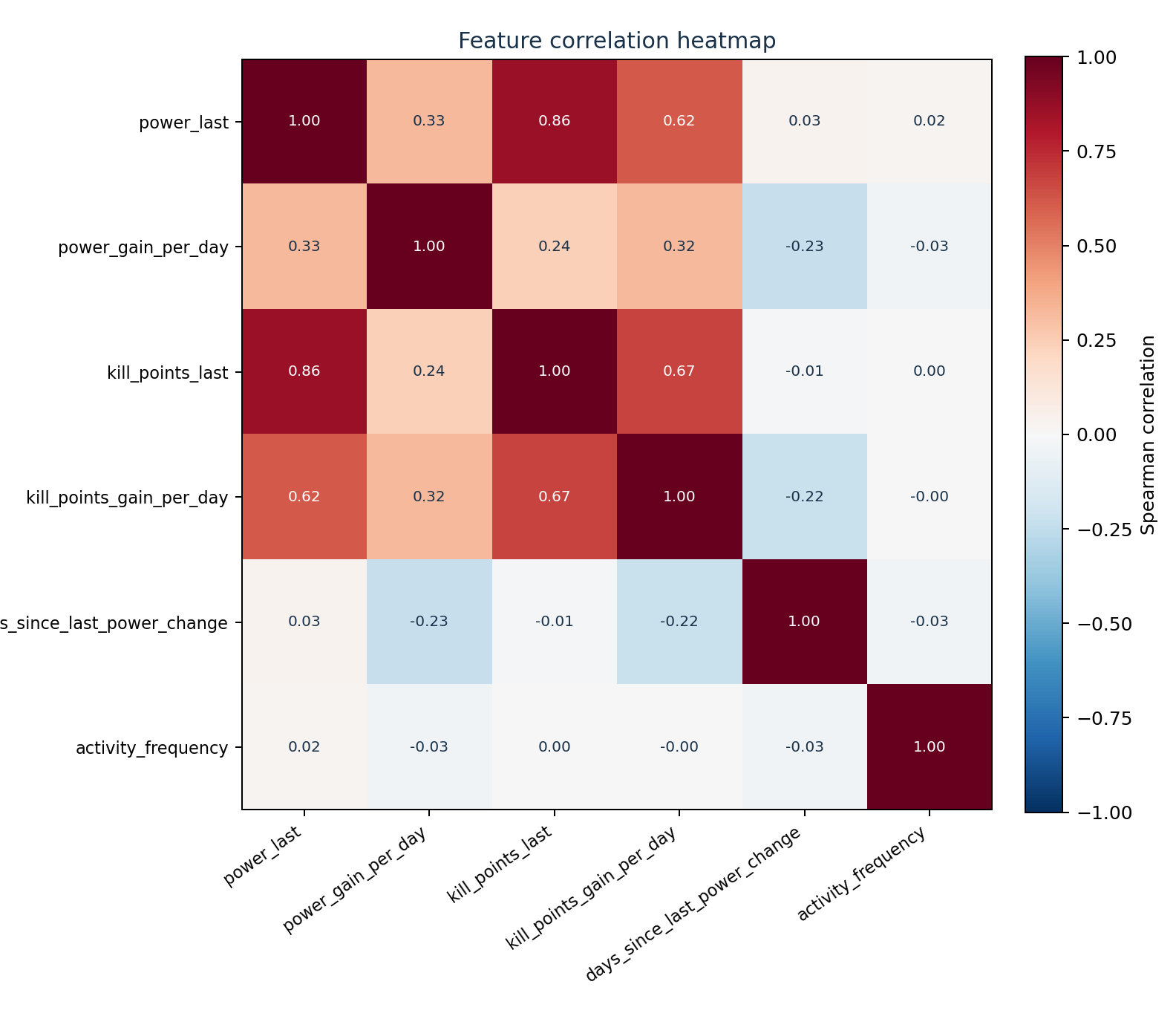
Ce type de figure est important parce qu’il montre que la représentation synthétique préserve une structure relationnelle, et pas seulement des variables isolées. En clair : le modèle retient que certaines grandeurs évoluent ensemble, tandis que d’autres évoluent en sens inverse. C’est précisément ce qu’un processus de synthèse guidé par espace latent est censé faire. Il produit des répondants et des cohortes non seulement plausibles individuellement, mais aussi collectivement structurés d’une manière qui reste analytiquement signifiante.
Portée et limites
Ces résultats n’impliquent pas que les panels synthétiques doivent remplacer toutes les formes de terrain ou tous les protocoles de mesure à fort enjeu. Ils montrent en revanche que Pollitics repose sur des programmes de recherche dotés d’une logique de validation explicite, de questions d’erreur mesurables et d’une volonté transparente de préserver la structure socio-démographique.
- Les répondants synthétiques ne sont pas des personnes réelles ; ce sont des simulations structurées construites à partir de choix de modélisation démographiques et comportementaux.
- Les benchmarks contre des sondages humains servent de tests de cohérence et de calibrage, pas de prétexte pour suraffirmer une certitude.
- La valeur scientifique de l’approche vient des contraintes explicites, de la préservation de structure latente et de workflows de validation auditables.
Publications associées
La bibliographie complète est disponible sur la page publications.
Ouvrir la page publicationsFAQ
Pollitics prétend-il remplacer toutes les études humaines ?
Non. Pollitics est positionné comme une couche exploratoire rapide pour tester messages, offres, concepts et réactions plus tôt, pas comme un remplacement général de toute étude humaine.
Pourquoi parler de recherche sur un site produit ?
Parce que cela aide les lecteurs à comprendre les racines méthodologiques du produit, au lieu de laisser l'expression panel synthétique comme un simple terme marketing.